Harness-First vs Reinforcement-First AI Agents
12/15/25
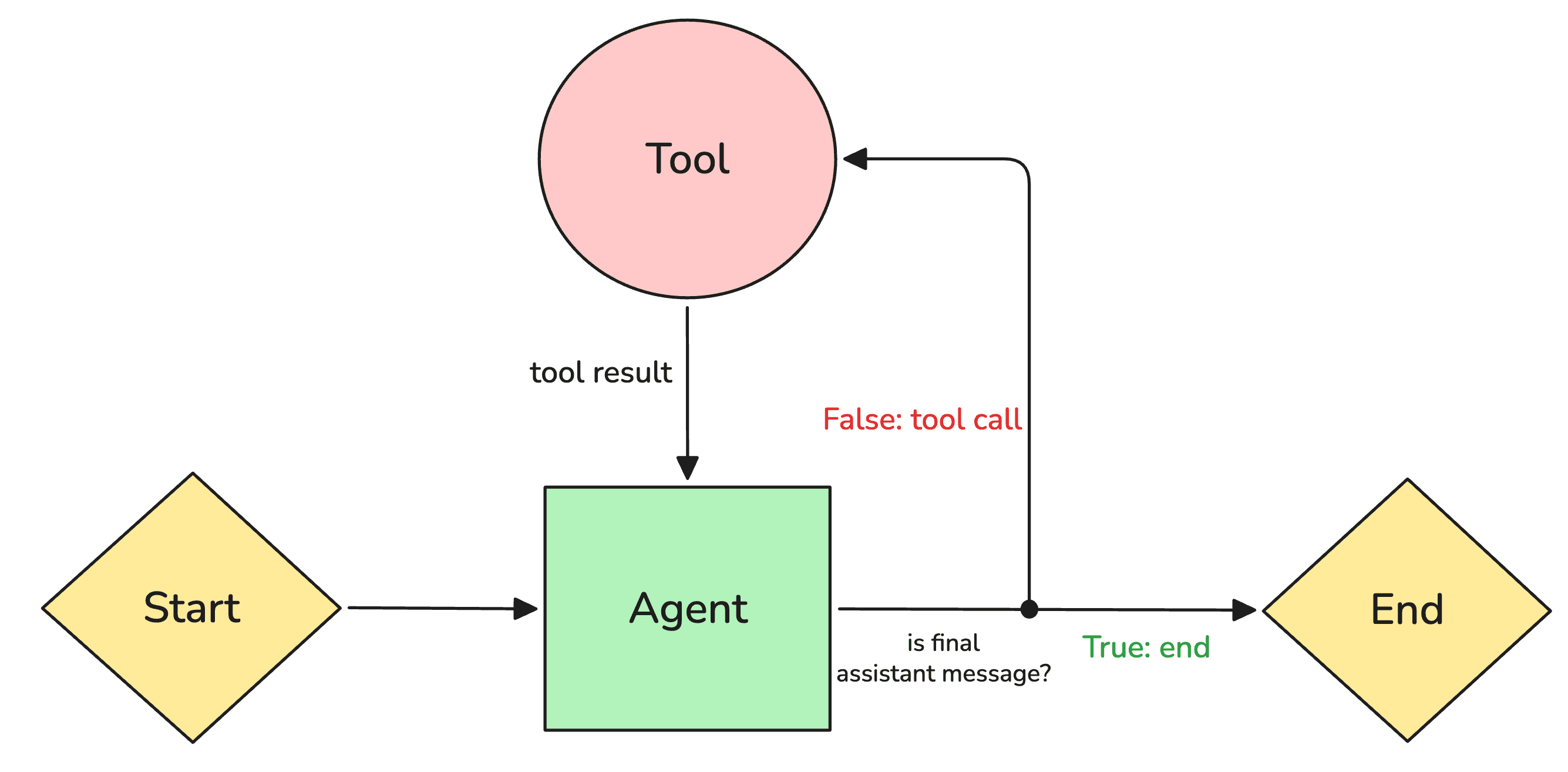
Most AI Agents fall into two broad categories:
1. Harness-first agents: These rely on tightly intertwined communication loops between multiple LLM calls. Agents are guided through complex interactions like prompt-chaining, routing, and parallelization. Popular implementations include CUGA[5] and Browser-Use[6].
2. RL agents: These rely on a simple loop behavior where an agent improves by optimizing a policy via gradient-based methods. The focus is on learning better reasoning behaviors directly instead of orchestrating many dependent LLM interactions. Tool-R1[2], for example, enables LLMs to perform general multi-step tool use through RL.
ReinforceNow was built with an rl-first (reinforcement-learning-first) approach to AI agent development.
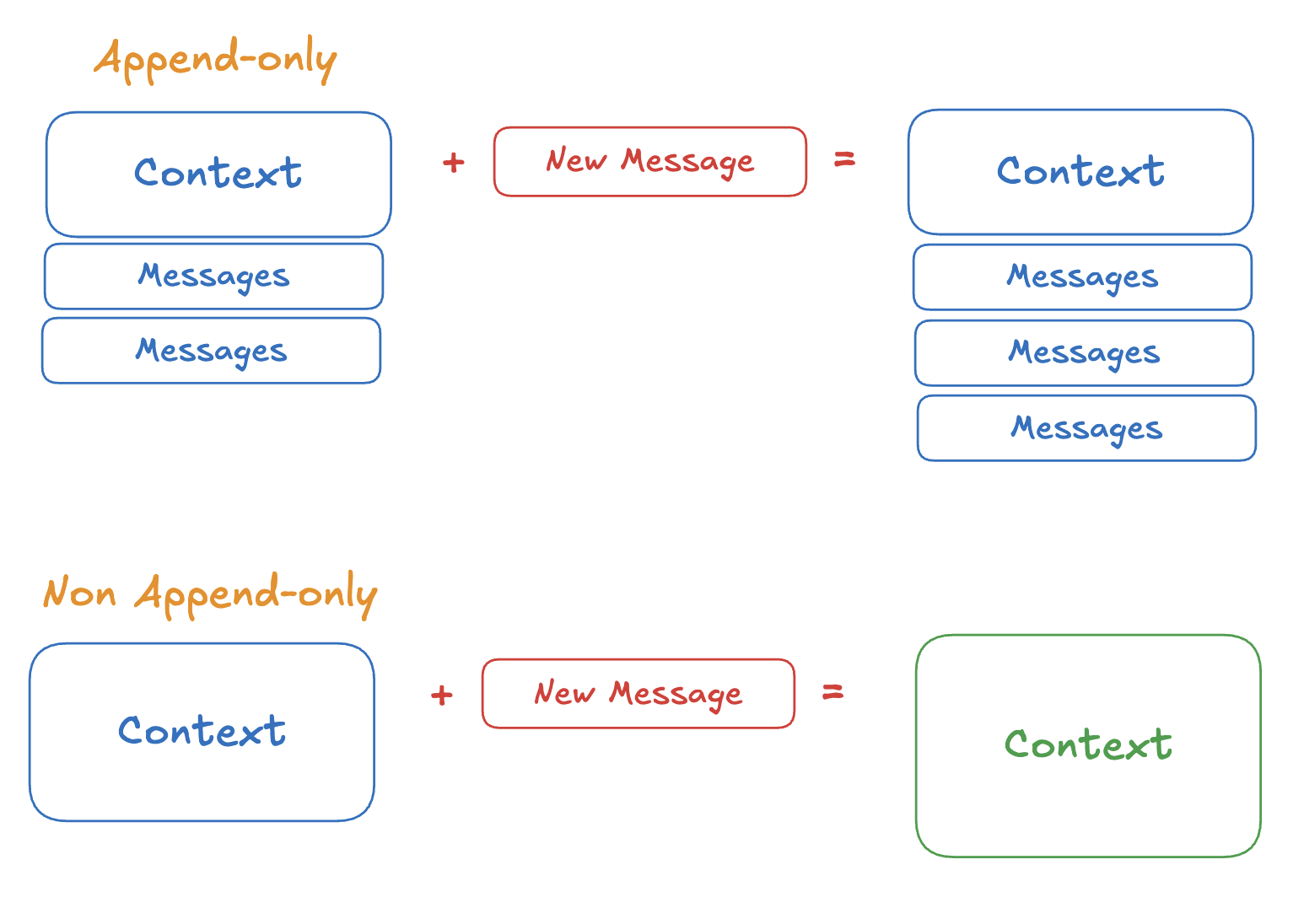
RL-first agents are append-only, meaning that the agent's context is extended each time by adding a new message. Harness-first agents tend to be non-append-only, meaning that the context is rewritten.
Each type has its strengths and weaknesses.
Harness-first agents are easy to implement. Engineers can quickly add routing and parallel workflows, introduce additional LLM post-processing steps, and incorporate new guardrails. Powerful frameworks like LangGraph[8] and CrewAI[9] make these workflows straightforward to build and extend.
However, this ease of implementation comes with trade-offs. Harness-first systems often grow in complexity as more loops, checks, and control logic are added. This expansion makes them harder to debug and understand which components are actually contributing to performance.
RL agents avoid piling on more workflow logic and instead focus on correcting the model's weaknesses by training it. For this reason, many rl-first agents consist of a single LLM connected to a set of tools, finetuned to perform tasks effectively. Models like Kimi K2 Thinking[3], when paired with just a few tools, can achieve outstanding results on benchmarks such as Humanity's Last Exam[4].
However, implementing the infrastructure to perform RL is very challenging. It also requires machine learning and reward modeling expertise to avoid training collapse or unintended behaviors such as reward hacking, where a model maximizes its reward in ways that violate the intended behavior.
Why not both?
The problem is that these two types of agents work against each other.
Harness-first agents are often not append-only, meaning the context of the LLM doesn't change only by adding new messages. Variables can change through the runtime of the agent.
For example, harness-first agents like CUGA[5] and Browser-Use[6] (some of the most widely used computer-use agents) do not operate in an append-only way. On every step, they rebuild a synthetic state prompt that overwrites the previous one. They take internal fields such as evaluation_previous_goal, memory, next_goal, and action_results, format them into <step_n> blocks, and inject them into a fresh <agent_history> section.
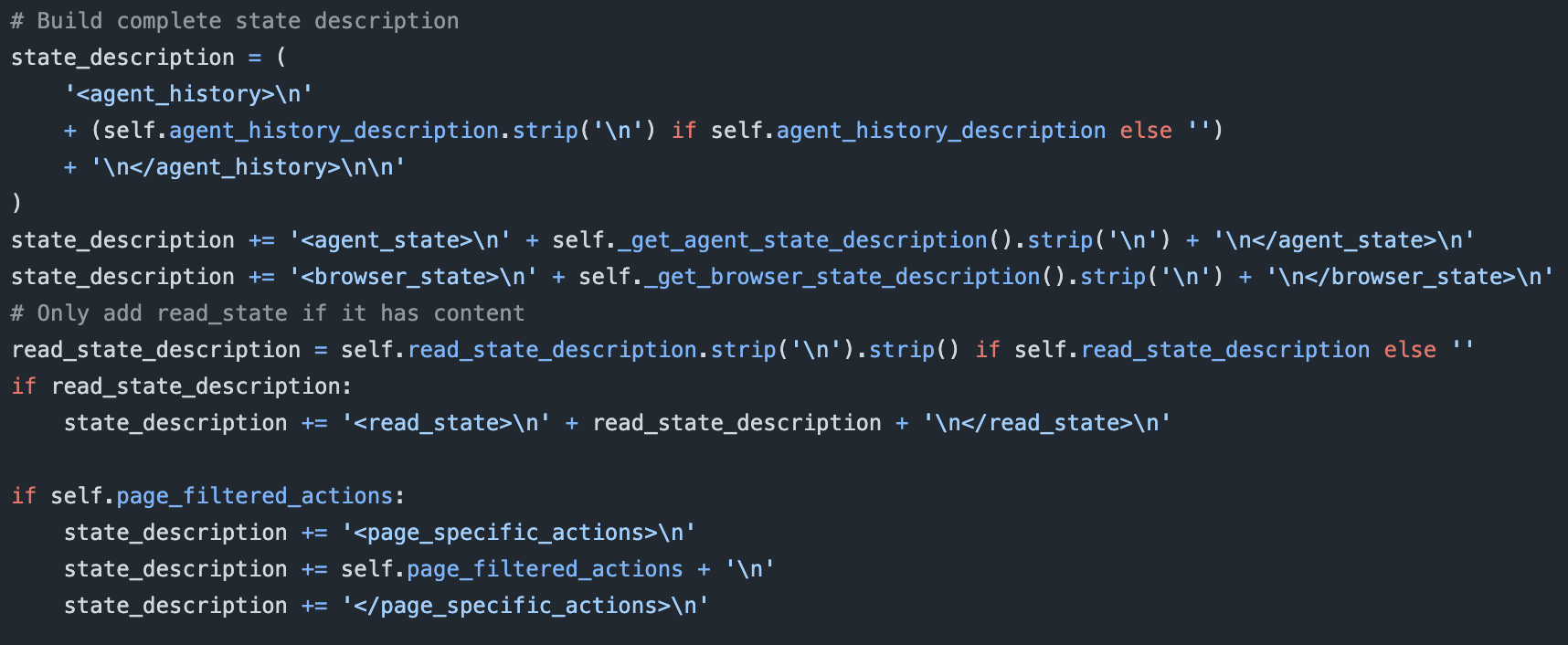
This block, along with regenerated <agent_state> and <browser_state> sections, replaces the prior state message entirely. The model is not seeing a growing, append-only conversation. It is seeing a continually rewritten control prompt, which is great for harness logic but incompatible with rl policies that rely on stable input distributions.
This behavior severely degrades the rl policy in reinforcement learning.
Another example is summarization compression. Often harness-only agents summarize parts of their message history to manage context. This again affects the rl policy, causing instability in training.
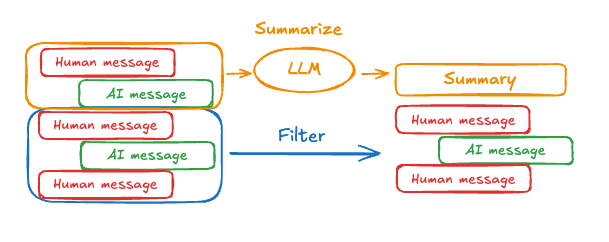
Harness-first and rl-first agents work against each other, and combining them is very tricky. There has been some research to address these issues. For example, recent work proposes a summarization-aware variant of GPRO that learns to compress context as part of the policy[7]. However, this field of study is not yet well understood and will likely develop in the coming years.
The democratization of RL
Up to now, most agent implementations have been harness-only, given the high barrier of entry for RL. However, that barrier is quickly becoming smaller with the democratization of compute and better understanding of the underlying alogorithms.
ReinforceNow makes it easier for non-ML practitioners to develop powerful AI using RL. You can easily develop tools and reward functions that align your model with the behavior you want. With time we hope to enable more harness primitive tools as they are better understood by the research community, enabling builders to quickly test and productionize their AI.
Learn how you can train your first agent with our quickstart tutorial.
References
[1] Yao, S., et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629
[2] Zhang, Y., et al. (2025). Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use. arXiv:2509.12867
[3] Moonshot AI. (2025). Kimi K2 Thinking. moonshotai.github.io/Kimi-K2/thinking
[4] Phan, L., et al. (2025). Humanity's Last Exam. arXiv:2501.14249
[5] CUGA Project. (2025). CUGA: The Configurable Generalist Agent. github.com/cuga-project/cuga-agent
[6] Browser-Use Contributors. (2025). Browser-Use: Make websites accessible for AI agents. github.com/browser-use/browser-use
[7] Chen, Y., et al. (2025). Scaling LLM Multi-turn RL with End-to-end Summarization-based Context Management. arXiv:2510.06727
[8] LangChain Inc. (2025). LangGraph: Build resilient language agents as graphs. github.com/langchain-ai/langgraph
[9] CrewAI Inc. (2025). CrewAI: Framework for orchestrating autonomous AI agents. github.com/crewAIInc/crewAI