Quickstart
We will finetune a Qwen/Qwen3-8B using supervised finetuning (SFT) on example conversations. SFT trains the model to mimic high-quality responses from your dataset.
Option A: Claude Code (Recommended)
After completing the installation, paste this prompt into Claude Code:
Finetune Qwen3-8B with RL on this math reasoning dataset:
https://huggingface.co/datasets/ReinforceNow/rl-single-math-reasoningOption B: Manual Setup
Step 1: Create a new folder and fetch the template:
rnow init --template sftStep 2: Start the training run:
rnow runYour terminal should look similar to this:
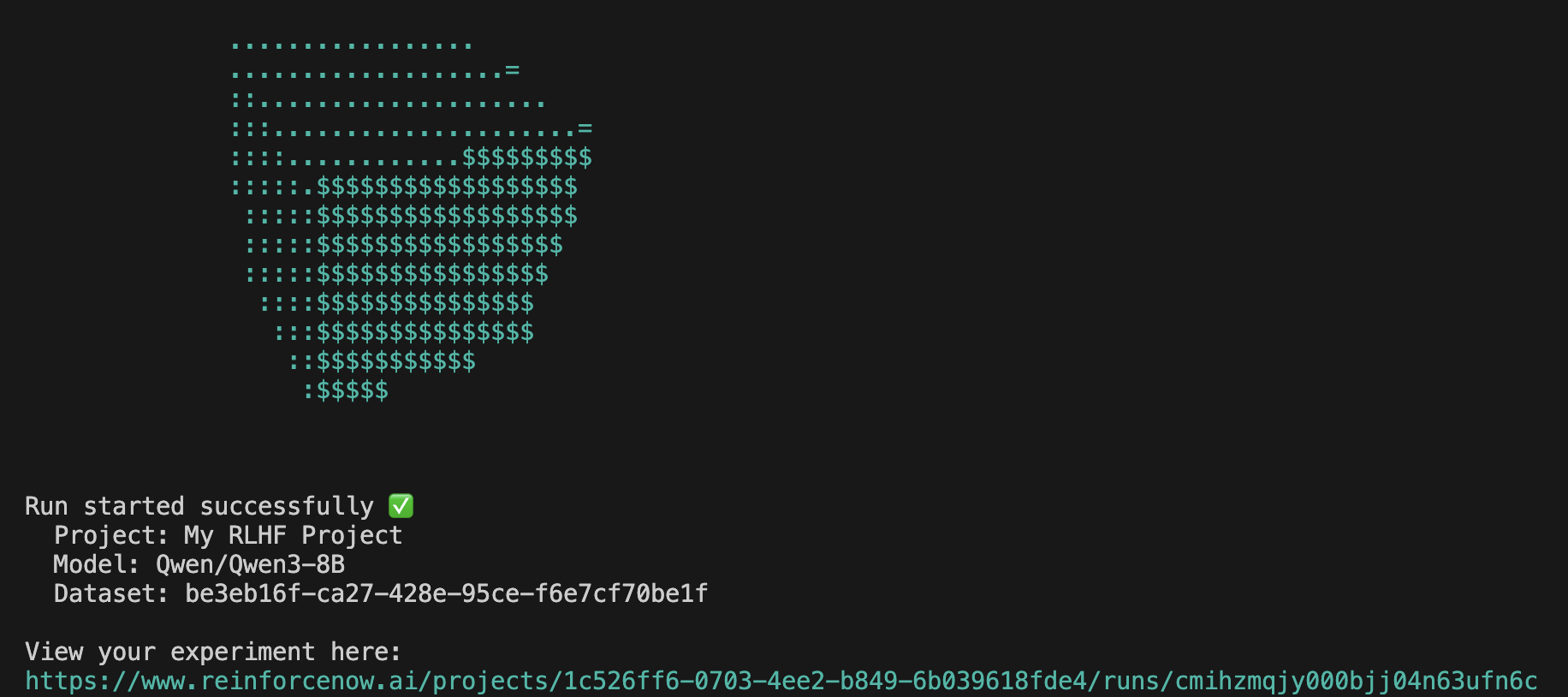
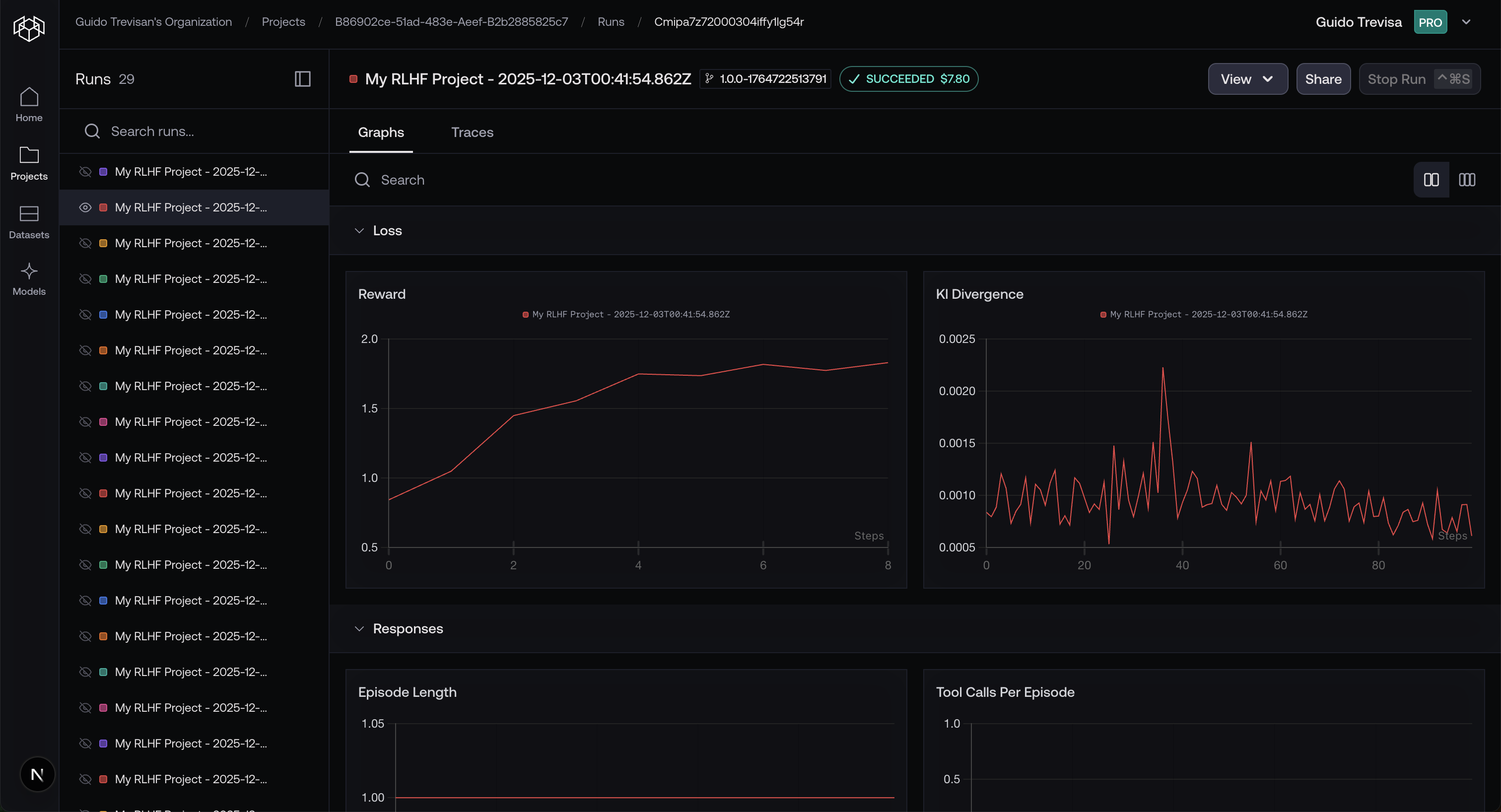
Step 3: View metrics and traces:
Navigate to your experiment link to view your model's performance. You can share your traces by clicking the share button, like this one: https://www.reinforcenow.ai/shared/runs/cmixqdocj000004l8cbkg2bkp
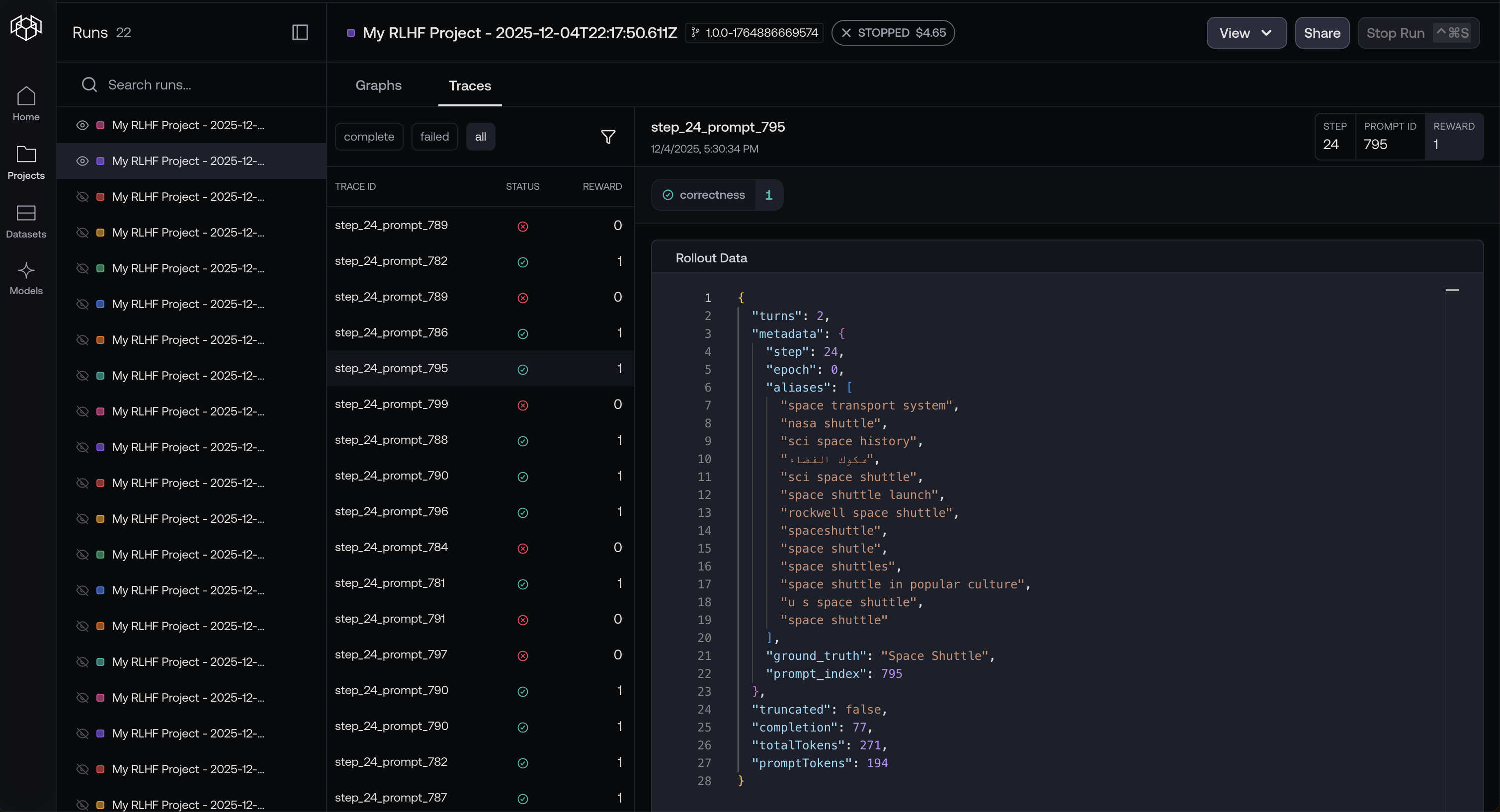
You can share your experiment traces by clicking the share button.